


Часто нам непонятно, почему некоторые из наших "белых" креативов банят, даже если на них нет явного контента 18+.
Сегодня рассмотрим то, как работают алгоритмы искусственного интеллекта и попробуем разобраться, на что обращать внимание при загрузке наших тизеров.
Данная система считывания инфы с картинок используется в Google и Facebook. Мы рассмотрим на примере Google.
Vision AI
Сервис Google Vision показывает, какую информацию определяет искусственный интеллект на изображении. Он точно видит человеческие эмоции, одежду, текст и части тела.
В описании сказано:

Пример использования в арбитраже и рекламе
Допустим, вы сделали креатив, но не знаете, как отнесется к нему Facebook или Google. Что делать?
Переходим в Google Vision и заливаем наше крео. Появляется окно с 8 вкладками (иногда меньше, зависит от сложности изображения и разнообразия объектов на нем). Рассмотрим каждую из них.
1. Faces (лица)
Видим, что на первой вкладке идет определение эмоций. В нашем случае - Joy (радость).

2. Objects (объекты)
На второй вкладке сервис показывает, что изображено на картинке

У нас он увидел Top (верх одежды), Banana (банан), Shirt (саму рубашку), Person (человек) и снова Top.
3. Labels (Ярлыки)
В третьей вкладки у нас лейблы - то, к каким категориям можно было бы отнести подобную картинку.

Здесь уже конкретика: T-shirt (футболка), Font (шрифт), Neck (шея), Recreation (отдых, но скорее в данном случае "развлечение"), Elbow (локоть) и Games (игры)
4. Logos (логотипы)
Четвертая вкладка появляется, если на вашем изображении присутствуют логотипы компаний.

Тут у нас четко опознался логотип ООН (United Nations)
5. Web
Во вкладке Web собрана информация о том, по каким поисковым запросам можно найти похожие картинки, а также приведены ссылки на оригиналы и копии исходных изображений

6. Text
Здесь робот пытается прочитать текст на изображении. Но наш текст на греческом, поэтому определяется некорректно. На английском работает гораздо лучше.

7. Properties (настройки)
В этой вкладке публикуется информация об основных цветах и том, как меняются ключевые точки изображения при разном соотношении сторон

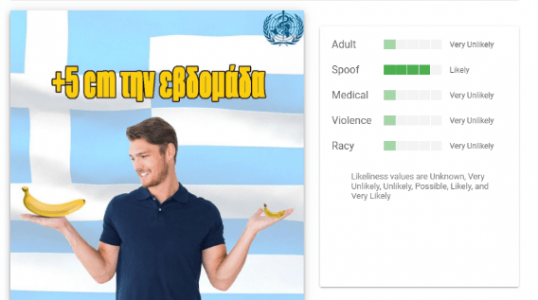
8. Safe Search (безопасность поиска)
Одна из важнейших вкладок - здесь содержится информация о том, к какой категории можно отнести контент на картинке в целом. В случае с нашим креативом это точно не контент для взрослых (Adult), но при этом явный обман (Spoof).

Учитывая последнюю вкладку, понимаем, что с большой долей вероятности, такой креатив не одобрит крупная рекламная сеть. А даже если и одобрит, то долго он не продержится")
Почему так вышло? Потому что когда на одной картинке есть логотип серьезной и очень крупной организации, при этом изображение радости, банана и упоминания сантиметров - с большой долей вероятности в хорошем контексте такое использоваться не будет.
Следовательно, нужно убирать какие-то элементы и пробовать снова.
Ссылка на Google Vision.
Сегодня рассмотрим то, как работают алгоритмы искусственного интеллекта и попробуем разобраться, на что обращать внимание при загрузке наших тизеров.
Данная система считывания инфы с картинок используется в Google и Facebook. Мы рассмотрим на примере Google.
Vision AI
Сервис Google Vision показывает, какую информацию определяет искусственный интеллект на изображении. Он точно видит человеческие эмоции, одежду, текст и части тела.
В описании сказано:
Google предлагает два способа получить представление о богатстве знаний, скрывающихся в Ваших изображениях. Наши мощные предварительно обученные модели Vision API быстро классифицируют изображения в тысячи категорий (таких как” парусник “или” Эйфелева башня") и распознают отдельные объекты, лица и слова
Пример использования в арбитраже и рекламе
Допустим, вы сделали креатив, но не знаете, как отнесется к нему Facebook или Google. Что делать?
Переходим в Google Vision и заливаем наше крео. Появляется окно с 8 вкладками (иногда меньше, зависит от сложности изображения и разнообразия объектов на нем). Рассмотрим каждую из них.
1. Faces (лица)
Видим, что на первой вкладке идет определение эмоций. В нашем случае - Joy (радость).
2. Objects (объекты)
На второй вкладке сервис показывает, что изображено на картинке
У нас он увидел Top (верх одежды), Banana (банан), Shirt (саму рубашку), Person (человек) и снова Top.
3. Labels (Ярлыки)
В третьей вкладки у нас лейблы - то, к каким категориям можно было бы отнести подобную картинку.
Здесь уже конкретика: T-shirt (футболка), Font (шрифт), Neck (шея), Recreation (отдых, но скорее в данном случае "развлечение"), Elbow (локоть) и Games (игры)
4. Logos (логотипы)
Четвертая вкладка появляется, если на вашем изображении присутствуют логотипы компаний.
Тут у нас четко опознался логотип ООН (United Nations)
5. Web
Во вкладке Web собрана информация о том, по каким поисковым запросам можно найти похожие картинки, а также приведены ссылки на оригиналы и копии исходных изображений
6. Text
Здесь робот пытается прочитать текст на изображении. Но наш текст на греческом, поэтому определяется некорректно. На английском работает гораздо лучше.
7. Properties (настройки)
В этой вкладке публикуется информация об основных цветах и том, как меняются ключевые точки изображения при разном соотношении сторон
8. Safe Search (безопасность поиска)
Одна из важнейших вкладок - здесь содержится информация о том, к какой категории можно отнести контент на картинке в целом. В случае с нашим креативом это точно не контент для взрослых (Adult), но при этом явный обман (Spoof).
Учитывая последнюю вкладку, понимаем, что с большой долей вероятности, такой креатив не одобрит крупная рекламная сеть. А даже если и одобрит, то долго он не продержится
Почему так вышло? Потому что когда на одной картинке есть логотип серьезной и очень крупной организации, при этом изображение радости, банана и упоминания сантиметров - с большой долей вероятности в хорошем контексте такое использоваться не будет.
Следовательно, нужно убирать какие-то элементы и пробовать снова.
Ссылка на Google Vision.